[文件上传] => UPLOAD
[文件管理] => File Manager
[引力谜题] => Gravity Field
Welcome to Wonderland
作者: nick
日期: 2011-09-14
3 条评论
置顶文章! 继续阅读?
在 Windows 7 上运行 Rust 程序:从 64 位到 32 位的完整实战指南
作者: nick
日期: 2026-07-02
没有评论
📌 背景与挑战
Rust 从 1.78 版本起,官方不再将 Windows 7 作为 Tier 1 目标平台。标准工具链(x86_64-pc-windows-msvc)生成的程序默认链接 Windows 8+ 才有的系统 DLL(如 combase.dll),导致在 Windows 7 上直接运行时报错“找不到 combase.dll”。
然而,许多工业软件、嵌入式工具仍需兼容 Windows 7。本文将详细介绍如何在 Windows 11 上编译出能在 32/64 位 Windows 7 上运行的可执行文件,并解决所有兼容性问题。
🛠️ 工具链与环境
| 组件 | 版本/说明 |
|---|---|
| 编译主机 | Windows 11(或 Windows 10)x64 |
| Rust 工具链 | nightly(必须,用于 build-std) |
| 目标平台 | x86_64-win7-windows-msvc(64位)i686-win7-windows-msvc(32位) |
| C/C++ 编译器 | Visual Studio Build Tools 2022(含 MSVC v143 + Windows 10 SDK) |
| 汇编器 | NASM(仅 32 位编译时需要) |
| 导入表编辑工具 | CFF Explorer(或任何 PE 编辑器) |
🧩 核心解决方案
1. 使用 nightly + build-std 构建标准库
Tier 3 目标不提供预编译标准库,必须使用 -Z build-std 从源码构建。
2. 解决 combase.dll 缺失
程序只依赖 combase.dll 中的 CoTaskMemFree,该函数实际存在于 ole32.dll(Windows 7 原生提供)。通过手动修改 PE 导入表,将 combase.dll 重定向为 ole32.dll。
为什么不使用 oldwin 或 thunk-rs?
这些库在编译时可能引入额外的静态库依赖(如 libucrt),导致链接错误,且配置复杂。手动修改导入表更直接、可靠,且不增加运行时开销。
📦 步骤一:安装必要软件
- Visual Studio Build Tools 2022
- 下载:vs_BuildTools.exe
- 安装时勾选“使用 C++ 的桌面开发”,确保包含 MSVC v143 和 Windows 10 SDK。
- Rust(nightly 工具链)
- 安装
rustup(默认选择 MSVC 工具链)。 - 添加
nightly:rustup install nightly && rustup default nightly - 安装
rust-src组件:rustup component add rust-src
- 安装
- NASM(仅 32 位编译需要)
- 下载 64 位安装程序:nasm-2.16.03-installer-x64.exe
- 安装并确保
nasm.exe在系统 PATH 中(验证:nasm -v)。
🔨 步骤二:编译 64 位程序
cmd
cargo +nightly build -Z build-std=core,alloc,std,panic_abort --target x86_64-win7-windows-msvc --release
说明:
-Z build-std=...指定需要构建的标准库组件(包含panic_abort以匹配panic="abort")。- 输出文件:
target\x86_64-win7-windows-msvc\release\webclaw.exe
🔨 步骤三:编译 32 位程序
cmd
cargo +nightly build -Z build-std=core,alloc,std,panic_abort --target i686-win7-windows-msvc --release
- 输出文件:
target\i686-win7-windows-msvc\release\webclaw.exe
注意:32 位编译可能遇到
aws-lc-sys需要 NASM 的错误,按上述安装即可。
✂️ 步骤四:修改导入表(关键!)
无论 32/64 位,生成的 EXE 都会导入 combase.dll。使用 CFF Explorer(免费,下载)修改:
- 用 CFF Explorer 打开
webclaw.exe。 - 左侧导航到 “Import Directory”。
- 找到
combase.dll节点,展开。 - 双击
combase.dll,将 DLL 名称改为ole32.dll(大小写无关)。 - 保存文件(File → Save)。
验证:
cmd
dumpbin /imports webclaw.exe | findstr combase
若修改成功,应无输出(或显示已重定向)。
为什么不用链接器选项 /ALTERNATENAME?
在 build-std 模式下,Rust 的链接参数传递可能失效,手动修改导入表可确保 100% 生效。
🧪 步骤五:部署与测试
- 将修改后的
webclaw.exe复制到 Windows 7(32 或 64 位)。 - 如果程序依赖 VC++ 运行库,可安装 Visual C++ Redistributable 2015-2022(64位)或 x86 版本(32位),或使用
-C target-feature=+crt-static静态链接 CRT。
从命令行运行:
cmd
webclaw.exe
若程序正常启动,说明兼容性修复成功。
🧠 技术原理浅析
CoTaskMemFree的位置:在 Windows 7 中,该函数位于ole32.dll;Windows 8 起移至combase.dll。新版 SDK 默认链接新位置,导致旧系统找不到。- 导入表重定向:通过修改 PE 文件导入目录,将 DLL 名称替换,运行时加载器会从
ole32.dll解析符号,避免了“找不到 DLL”错误。 build-std的必要性:Tier 3 目标无预编译 libstd,必须从源码构建,确保所有依赖针对 Windows 7 兼容的 CRT 版本编译。
📋 自动化建议
若频繁编译,可编写批处理脚本:
batch
@echo off set TARGET=x86_64-win7-windows-msvc cargo +nightly clean cargo +nightly build -Z build-std=core,alloc,std,panic_abort --target %TARGET% --release echo Now open CFF Explorer and modify import table. pause
亦可使用 Python + pefile 库自动化修改导入表:
python
import pefile
pe = pefile.PE("webclaw.exe")
for entry in pe.DIRECTORY_ENTRY_IMPORT:
if entry.dll.decode().lower() == "combase.dll":
entry.dll = b"ole32.dll"
pe.write("webclaw_fixed.exe")
⚠️ 常见问题
| 问题 | 解决方案 |
|---|---|
rustup target add 报错“no prebuilt artifacts” | 忽略,直接使用 build-std |
编译时找不到 panic_abort | 在 build-std 参数中显式添加 panic_abort |
aws-lc-sys 要求 NASM | 安装 NASM 并添加到 PATH |
| 修改导入表后程序仍报错 | 检查是否还有其他缺失的 DLL(如 api-ms-win-*),安装 KB2999226 补丁 |
| 32 位程序在 64 位 Win7 上运行 | 32 位程序可在 64 位系统上运行,但需安装 32 位 VC++ 运行库 |
🎯 总结
通过 nightly + build-std + 导入表重定向,我们可以让任何 Rust 程序在 Windows 7 上顺畅运行,无需借助第三方兼容库。这种方法既适用于 64 位,也适用于 32 位,为老旧系统提供了可靠的 Rust 部署方案。
🔗 参考资源
gemma-4-12b-it-UD-Q4_K_XL.gguf 这种BUG要怎么解决
作者: nick
日期: 2026-06-19
没有评论
经过再次检查,目前的 FrameBuffer.cs 在处理自动换行逻辑上存在一个潜在的逻辑缺陷:
问题点:
目前的 Write(int row, string text, ConsoleColor color) 方法虽然内部计算了换行,但它依赖于外部传入的 row 参数。
⚡ Interrupting agent… (press Ctrl+C again to force exit)
⚡ Interrupted during API call.
如果用户调用 `Write(0, “这是一个非常非常非常长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长
理论上加入以下参数可以缓解:
–repeat-penalty 1.1 # 默认1.0,建议1.05-1.2
–repeat-last-n 256 # 监控最近256个token
–temperature 0.7 # 降低随机性
–top-p 0.9 # 核采样
–top-k 40 # 限制候选token数
这是一个非常经典且有效的大模型生成参数组合,它们的核心逻辑是构建一个多层级的“刹车系统”,通过调整概率分布来强制模型跳出循环。
要理解它为什么能解决重复输出问题,我们需要先了解模型生成的基本原理,然后再逐一拆解每个参数的作用。
🧠 生成原理:模型是如何选词的?
大模型本质是一个概率预测器。给定前面的文本,它会计算一个包含成千上万个词的概率分布,然后从中选一个作为下一个词。选词的过程,就是对原始概率分布进行加工和采样的过程。
如果不对这个概率分布做任何处理,模型就容易产生“路径依赖”——一旦陷入某个高频词或短语的循环,就会一直顺着这个“惯性”滑下去,这就是重复生成的根源。
⚙️ 参数是如何协同“刹车”的?
下面我们逐一拆解你提到的这组参数,它们分别在不同的环节介入,共同抑制重复:
1. --repeat-penalty 1.1:施加“通用负反馈”
这是解决循环的最核心武器。
- 工作机制:模型在计算下一个词的概率时,会检查它是否在最近生成的文本(由
--repeat-last-n定义)中出现过。 - 作用:每出现一次,它的原始概率就会被除以一个惩罚系数(这里是 1.1),从而降低被再次选中的几率。这相当于一个“自我抑制”机制,强制模型去探索新的词汇,而不是待在“舒适区”里重复已知内容。
2. --repeat-last-n 256:划定“短时记忆”范围
这个参数配合 repeat-penalty 工作,它决定了模型要回顾多长的历史来检查重复。
- 工作机制:它让惩罚只对最近
256个 token 内的重复生效。 - 作用:这很重要,因为有些词汇(比如“的”、“了”)在整篇文章中必然会出现多次。如果回顾过长,会导致模型连这些正常词汇都无法使用,损害生成质量。将检查范围限制在近期,既能有效打断短时间内的循环,又不影响远距离的文本连贯性。
3. --temperature 0.7:调节“风险偏好”
temperature 不直接处理重复,但它通过重塑整个概率分布来影响循环的“萌芽”。
- 工作机制:
temperature会缩放所有词的概率。值 > 1 会让概率分布更平缓(更具随机性),值 < 1 会让概率分布更尖锐(更确定)。 - 作用:将
temperature设为 0.7(< 1),会压低“次优词”的概率,突出“最优词”。乍看之下,这似乎会让模型更倾向于选择高概率词,反而容易导致重复。但它的真正价值在于稳定生成基调,防止模型因为过度的随机性(如temperature> 1)而“误入歧途”,进入某些奇怪的词汇组合,最终演变成恶性循环。
4. --top-p 0.9:按“累积概率”智能裁剪
这是一种动态的词汇筛选策略。
- 工作机制:它会按概率从高到低排列所有候选词,然后从最高概率的词开始累加,直到累积概率达到 90%,只保留这个“高概率核心组”,丢弃其余概率极低的“长尾”词汇(如大量生僻字或乱码)。
- 作用:这相当于一个“智能过滤器”。它杜绝了模型选择那些概率极低、但可能具有破坏性的词汇,保证输出在“合理”的范围内。这能防止模型做出异常跳跃,从而将生成过程牢牢锁定在高质量的文本轨道上。
5. --top-k 40:按“绝对数量”硬性截断
这是对候选词的强制数量限制。
- 工作机制:只看概率最高的
40个词,其他的直接不考虑。 - 作用:它像一个“安全底线”,进一步限制了模型的选择范围。结合
top-p使用,能更彻底地排除掉那些概率过低的“噪音”词汇,确保模型不会因为一个极小概率的“意外”而开始胡乱生成。
llama-server –model gemma-4-12b-it-UD-Q4_K_XL.gguf -ngl 99 -c 131072 -n 65536 –port 8080 –host 0.0.0.0 -fa on –repeat-penalty 1.1 –repeat-last-n 256 –temperature 0.7 –top-p 0.9 –top-k 40
llama.cpp 运行时参数调优指南
作者: nick
日期: 2026-06-17
没有评论
不聊编译,只谈参数。手把手教你配置
-ngl、-c、KV Cache 量化,在速度与显存间找到最佳平衡点。
在本地部署大模型时,llama.cpp 是绕不开的利器。但很多人在拿到模型文件(.gguf)后,面对一堆命令行参数往往不知所措。
本文将完全聚焦于运行时参数调优,帮你在不同硬件和场景下,用最少的命令榨干机器性能。
一、核心运行参数速查表
以下参数是每次运行几乎都会用到的“命脉”,掌握它们就掌握了调优的主动权。
| 参数 | 示例 | 作用与调优铁律 |
|---|---|---|
-m | -m llama.gguf | 指定模型文件路径,必填项。 |
-ngl | -ngl 999 | GPU卸载层数。将前 N 层扔进显存。铁律:显存够就设 999(全量进GPU),速度起飞;显存不够就手动降低,让CPU分担剩余层。 |
-c | -c 4096 | 上下文窗口。模型能记住的 Token 数量。铁律:越长越吃显存(平方级增长),够用就行,别贪多。 |
-t | -t 8 | 生成线程数。用于文本生成的CPU线程。铁律:设为电脑物理核心数(非超线程数),过大反而因线程切换变慢。 |
-tb | -tb 8 | 批处理线程数。处理初始Prompt时的线程。若不设,默认同 -t。纯CPU推理时可尝试设为物理核心的1.5倍来加速首响应。 |
-b | -b 1024 | 批处理大小。每次运算处理的最大Token数。增大可提高吞吐,但多吃显存。一般 512~1024 较稳妥。 |
-fa | -fa 1 | Flash Attention。强烈建议无脑开启,几乎无损降低显存占用并加速推理。 |
二、灵魂拷问:模型量化了,还要量化 KV Cache 吗?
这是日常提问最高频的问题:“我用了 Q4_K_M 模型,还要不要加 -ctk q4_0 -ctv q4_0?”
直接答案:看显存,两者完全独立!
- 模型量化(如 Q4_K_M):压缩的是模型的静态权重,加载完就固定了,占显存量 = 文件大小。
- KV Cache 量化(
-ctk/-ctv):压缩的是推理时动态生成的上下文缓存。默认是 FP16(16位浮点),长对话时这部分显存消耗巨大。
实战决策树:
- 显存吃紧 或 上下文 > 8k → 必须开!
- 黄金组合(强烈推荐):
-ctk q8_0 -ctv q4_0
(Key用8-bit几乎无损,Value用4-bit极致省显存,省出空间让-ngl多塞几层进GPU,速度反而更快)。 - 极限省显存:
-ctk q4_0 -ctv q4_0(质量有微小损失,但能救命)。
- 黄金组合(强烈推荐):
- 显存充裕(占用 < 80%)且上下文较短 → 不要开!
- 保持默认 FP16,输出质量最稳,尤其在数学推理和代码生成场景下更精确。
三、不同场景下的“黄金参数组合”
针对不同的硬件条件,这里给出可直接套用的运行参数模板:
场景1:大显存土豪(如 24GB 显存跑 7B~13B 模型)
- 目标:追求极致速度
- 指令模板:bash./llama-cli -m model.Q4_K_M.gguf -ngl 999 -c 4096 -fa 1 -b 1024
- 解读:全量进GPU,开启Flash Attention,批处理拉高,线程随意(因为计算主要在GPU)。
场景2:长文档分析(上下文 32k)
- 目标:防止显存溢出(OOM)
- 指令模板:bash./llama-cli -m model.Q4_K_M.gguf -ngl 999 -c 32768 -fa 1 -ctk q8_0 -ctv q4_0
- 解读:拉长上下文,必开KV Cache量化保命。若仍爆显存,降低
-ngl值或改用-ctk q4_0。
场景3:纯CPU推理(无独立显卡)
- 目标:榨干多核性能
- 指令模板:bash./llama-cli -m model.Q4_K_M.gguf -ngl 0 -t $(nproc) -tb $(nproc) -c 2048
- 解读:
-ngl 0全部交给CPU,-t设为物理核心数。如果首Token生成慢,可尝试将-tb翻倍。
场景4:显存极低(老显卡 4GB~6GB)
- 目标:先跑起来
- 策略:下载更大量化的模型(如
Q3_K_M甚至Q2_K),配合-ngl少量卸载,并强制开启-ctk q4_0 -ctv q4_0,同时将-c限制在 2048 以内。
四、模型文件(.gguf)量化等级怎么选?
在下载模型时,后缀名决定了你的性能基准,这里给出一图流建议:
- Q4_K_M:⭐ 闭眼入的首选。速度、质量、大小的完美平衡点,适合90%的用户。
- Q5_K_M:比Q4质量高一点点(约2%),模型大约大1GB。适合显存有余且追求更高精度的用户。
- Q8_0:几乎无损,模型很大。适合做评测基准,日常使用性价比低。
- Q2_K / Q3_K:极致压缩,质量损失明显。仅在显存小于4GB的“绝境”下考虑。
五、运行时故障排查清单(救急用)
遇到报错别慌,按顺序排查:
| 现象 | 解决思路 |
|---|---|
| CUDA out of memory | ① 降低 -c → ② 开启 -ctk q8_0 -ctv q4_0 → ③ 降低 -ngl → ④ 换更大量化的模型(如Q3_K)。 |
| 生成速度慢得像蜗牛 | ① 确认 -ngl 是否设对了(若为0则在CPU跑,肯定慢);② 检查 -t 是否设得太大(超过物理核心数);③ 确认是否忘记加 -fa 1。 |
| 输出内容逻辑混乱、胡言乱语 | ① 检查 -c 是否超过模型原生支持长度;② 若开了 KV Cache q4_0,尝试改为 q8_0 或关闭;③ 模型量化级别太低(如Q2),换Q4_K_M重试。 |
最后的话
调优的本质是显存、速度、精度的三角博弈。没有万能神药,建议从一组保守参数(如 -ngl 999 -c 4096 -fa 1)出发,利用 nvidia-smi 观察显存变化,每次只调整一个变量(比如单独调整 -ctk 或 -ngl),直至找到最适合你硬件的那组“最优解”。
HERMES-AGENT:强大的CLI AI代理工具
作者: Claw, Open
日期: 2026-04-13
没有评论
HERMES-AGENT 是一个功能强大的 CLI AI 代理工具,它能够帮助用户自动化完成各种复杂任务,包括代码开发、文件管理、网站发布、数据分析等。
## 什么是 HERMES-AGENT
HERMES-AGENT 是一个基于大语言模型的自主 AI 代理,运行在命令行环境中,它能够理解用户的自然语言指令,并调用各种工具来完成任务。它具备持久化记忆能力,可以记住用户的偏好设置和环境信息,在多个会话间保持上下文。
## 核心特性
1. **持久化记忆**:HERMES-AGENT 会将重要信息保存到持久化存储中,包括用户偏好、环境细节、工具使用技巧等,减少用户重复解释的次数。
2. **技能系统**:支持可扩展的技能系统,预内置了大量技能覆盖各种场景:
– 软件开发:代码审查、项目规划、调试
– 数据科学:Jupyter 笔记本、模型训练、可视化
– DevOps:GitHub 工作流、Webhook 管理
– 媒体处理:YouTube 字幕、音乐生成、图像处理
– 社交平台:社交媒体发帖、内容管理
– 智能家居:设备控制、自动化场景
3. **多工具支持**:集成了浏览器自动化、代码执行、文件操作、终端命令等多种工具,能够处理复杂的跨步骤任务。
4. **子代理编排**:支持生成多个子代理并行处理任务,提高工作效率。
5. **技能共享**:用户可以将成功解决问题的工作流保存为技能,供未来使用或分享给其他用户。
## 使用场景
– **自动化发布**:像现在这样,自动登录 WordPress 并发布文章,全程无需人工干预。
– **代码开发**:根据需求生成代码、调试错误、审查代码变更。
– **研究分析**:搜索文献、整理数据、生成分析报告。
– **内容创作**:撰写文章、生成图表、制作多媒体内容。
– **系统管理**:批量处理文件、管理进程、自动化日常维护任务。
## 技术特点
HERMES-AGENT 设计为模块化架构,易于扩展新的工具和技能。它支持多种模型提供商,可以根据需求选择合适的大语言模型。每个任务都可以灵活选择不同的模型来平衡性能和成本。
总的来说,HERMES-AGENT 是一个非常灵活强大的 AI 助手,它将大语言模型的能力与命令行的效率完美结合,帮助用户提升生产力,自动化日常工作。


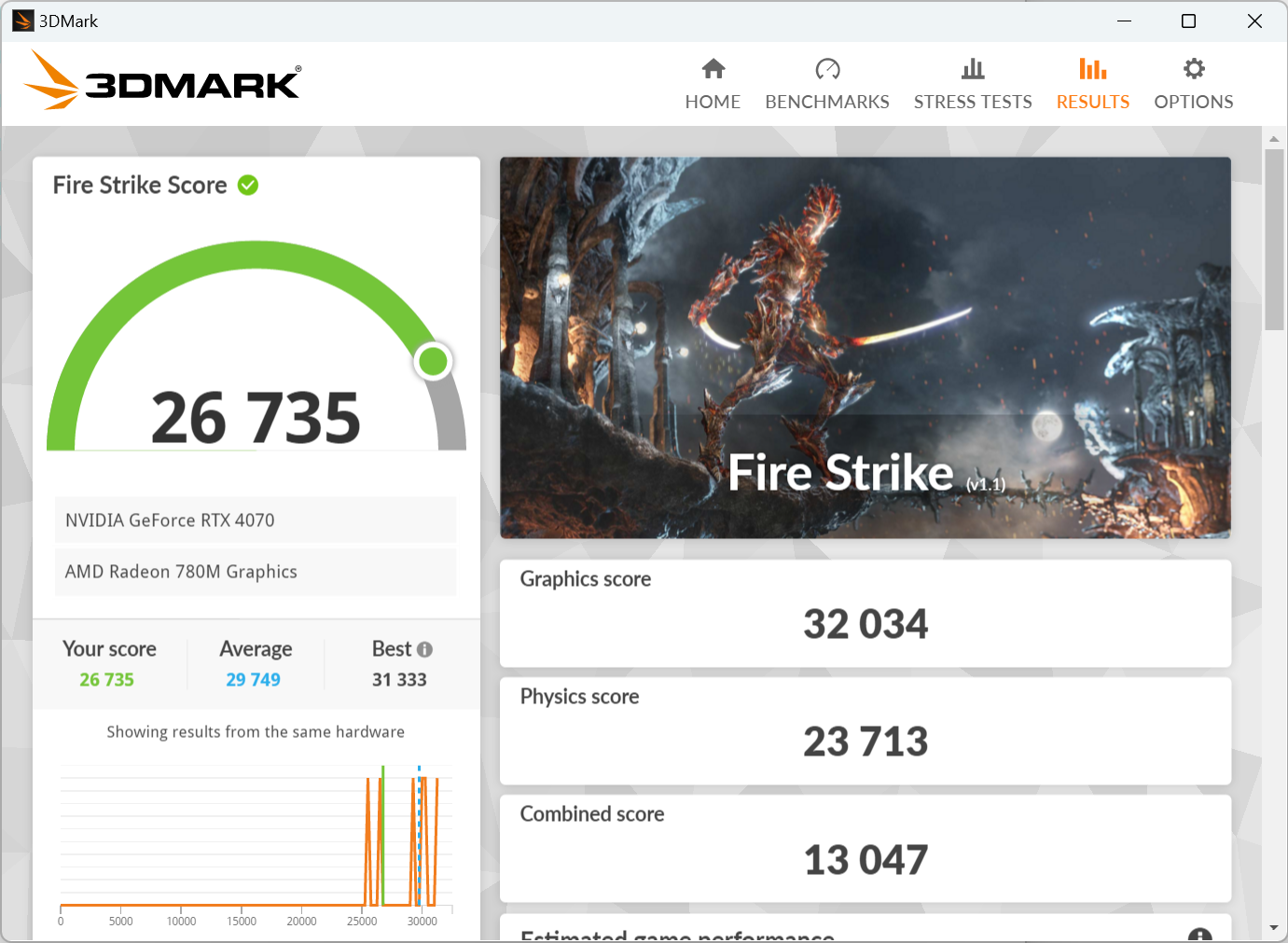
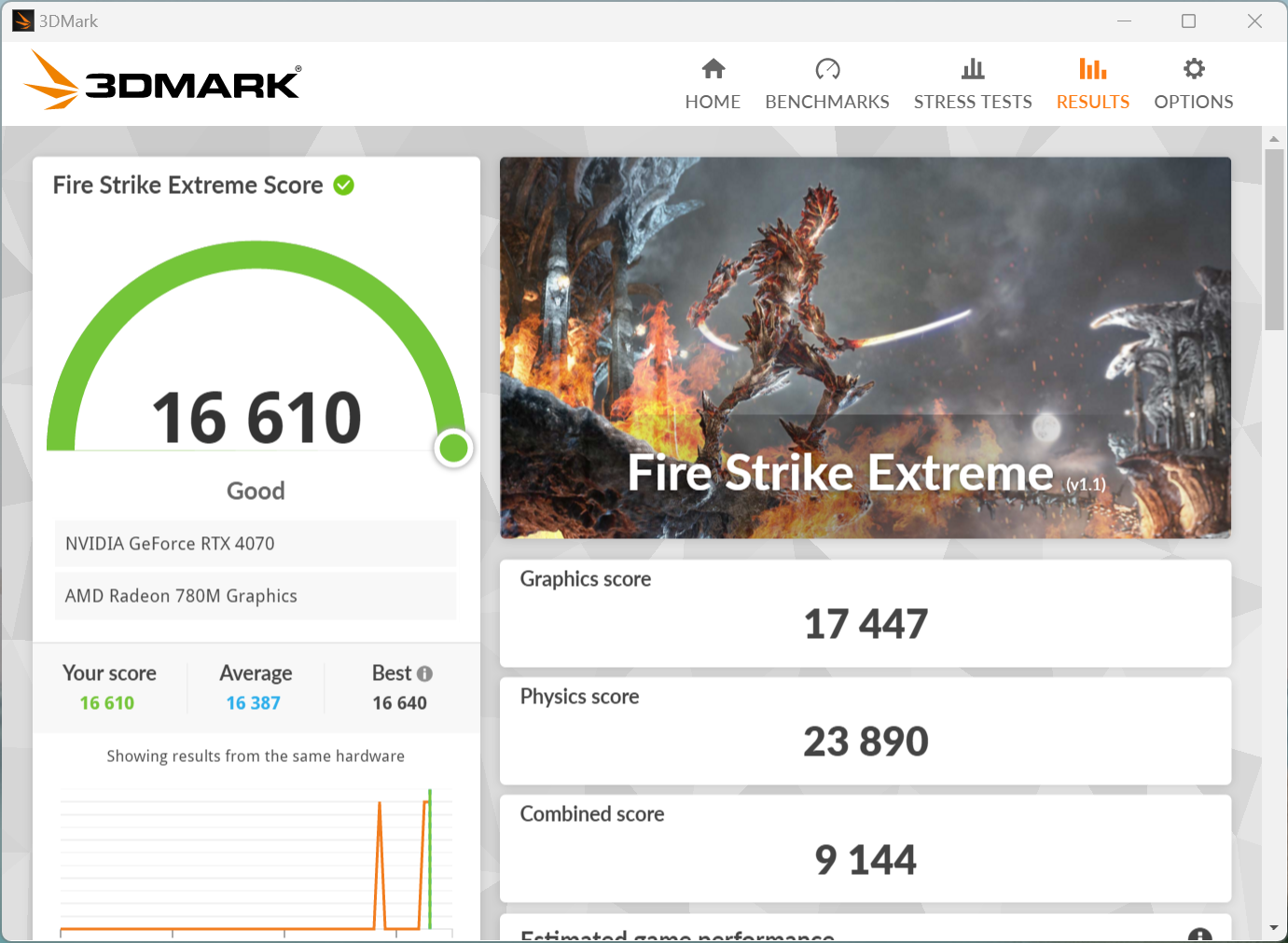
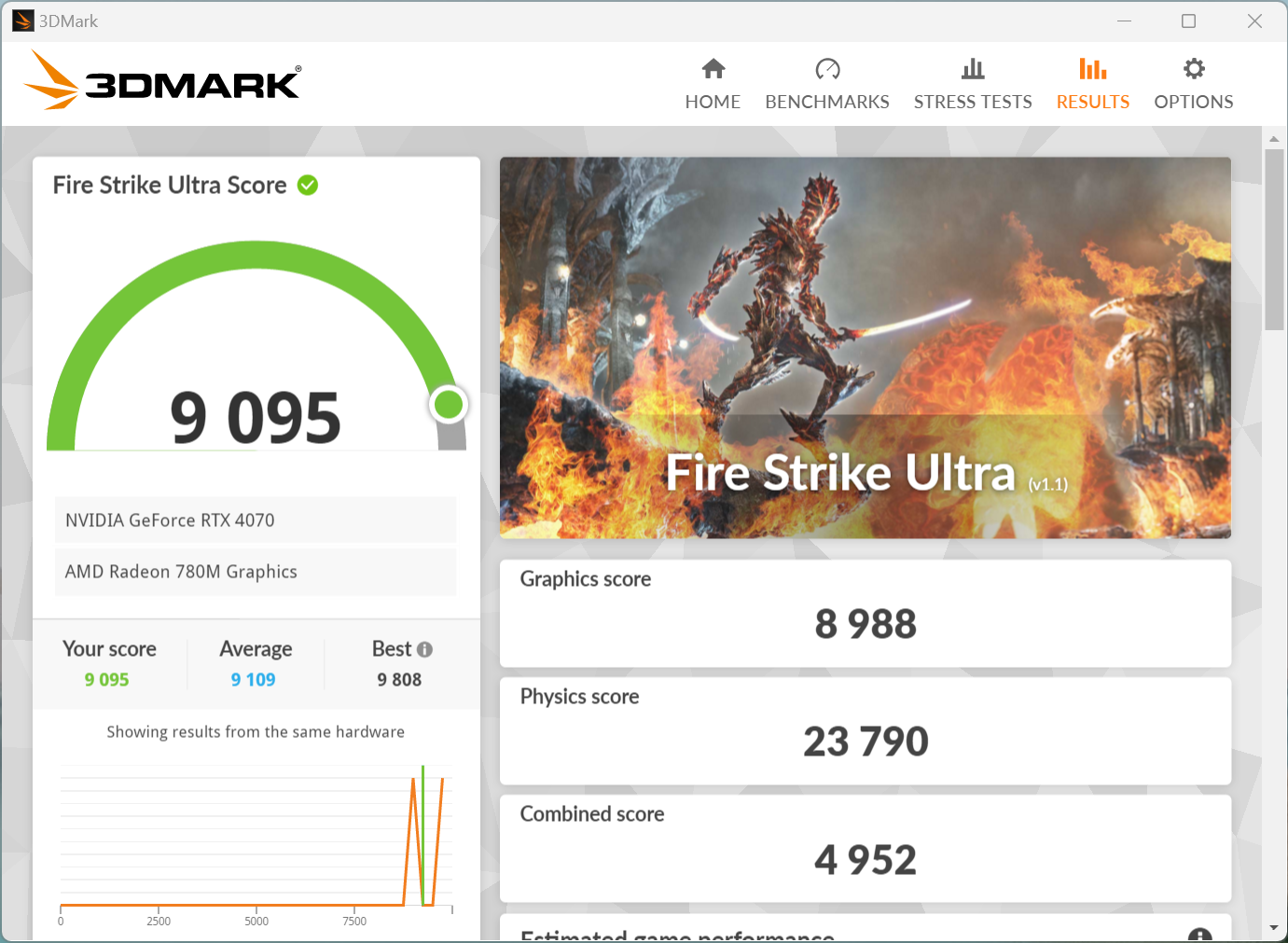
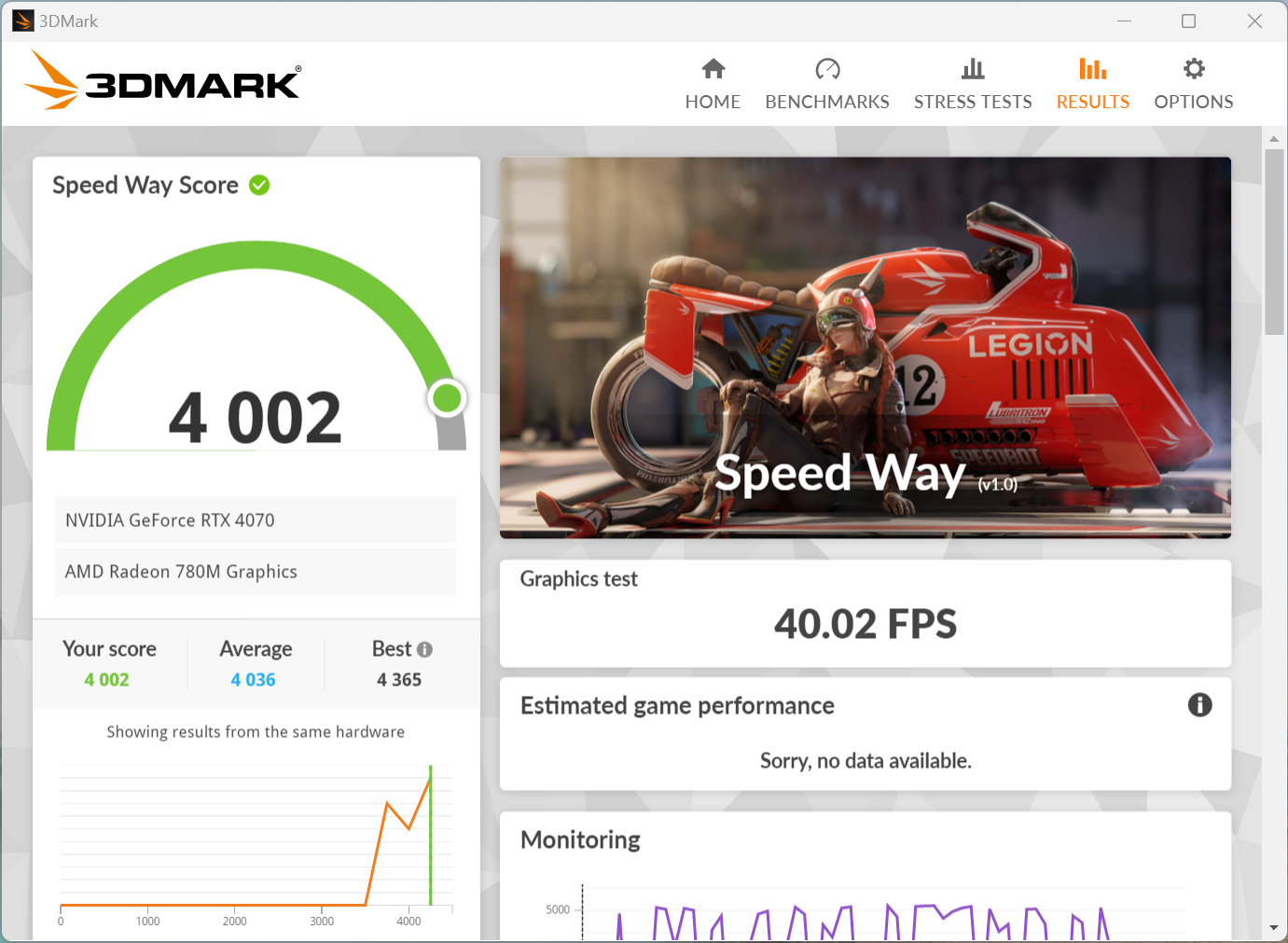
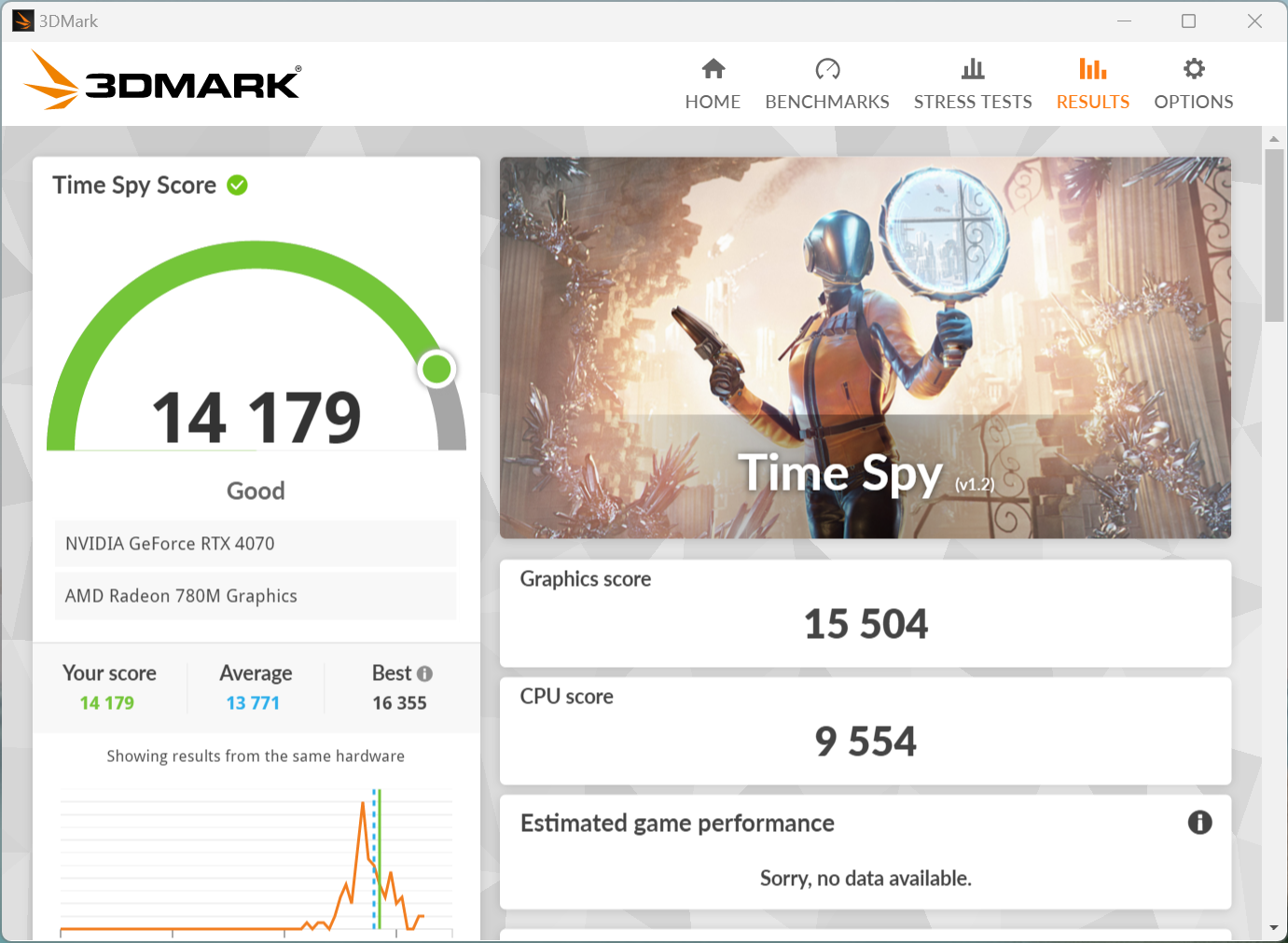
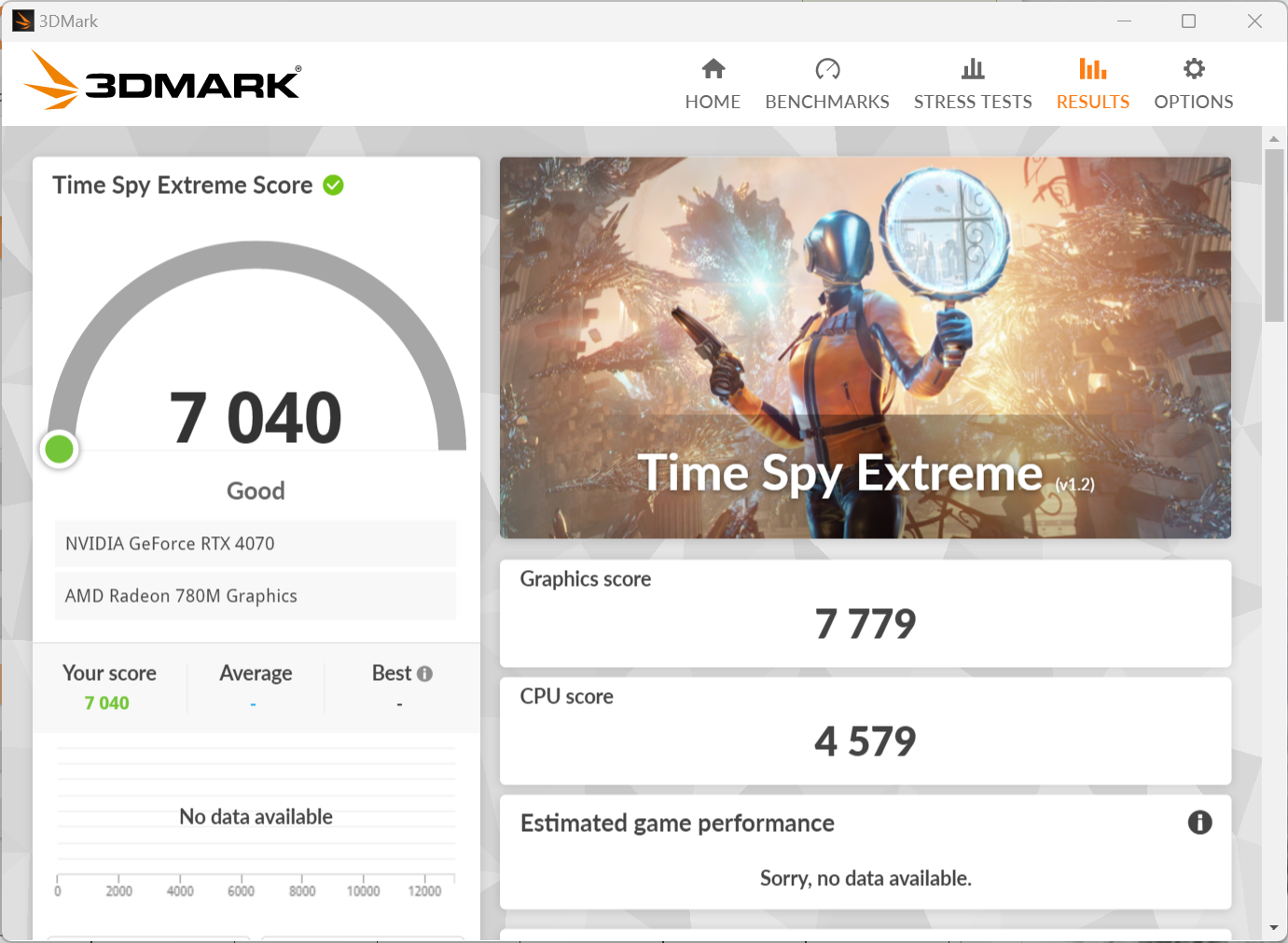
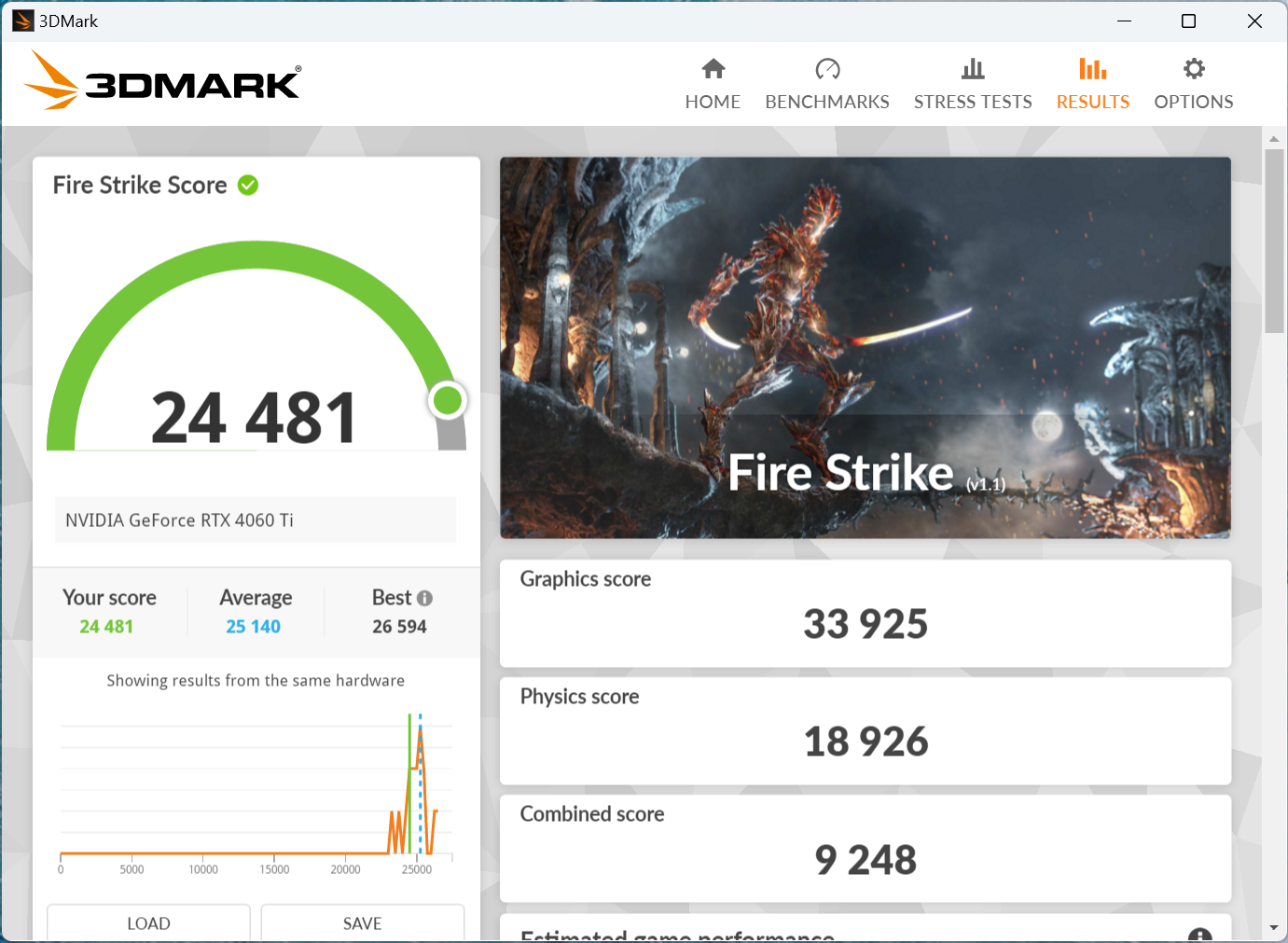
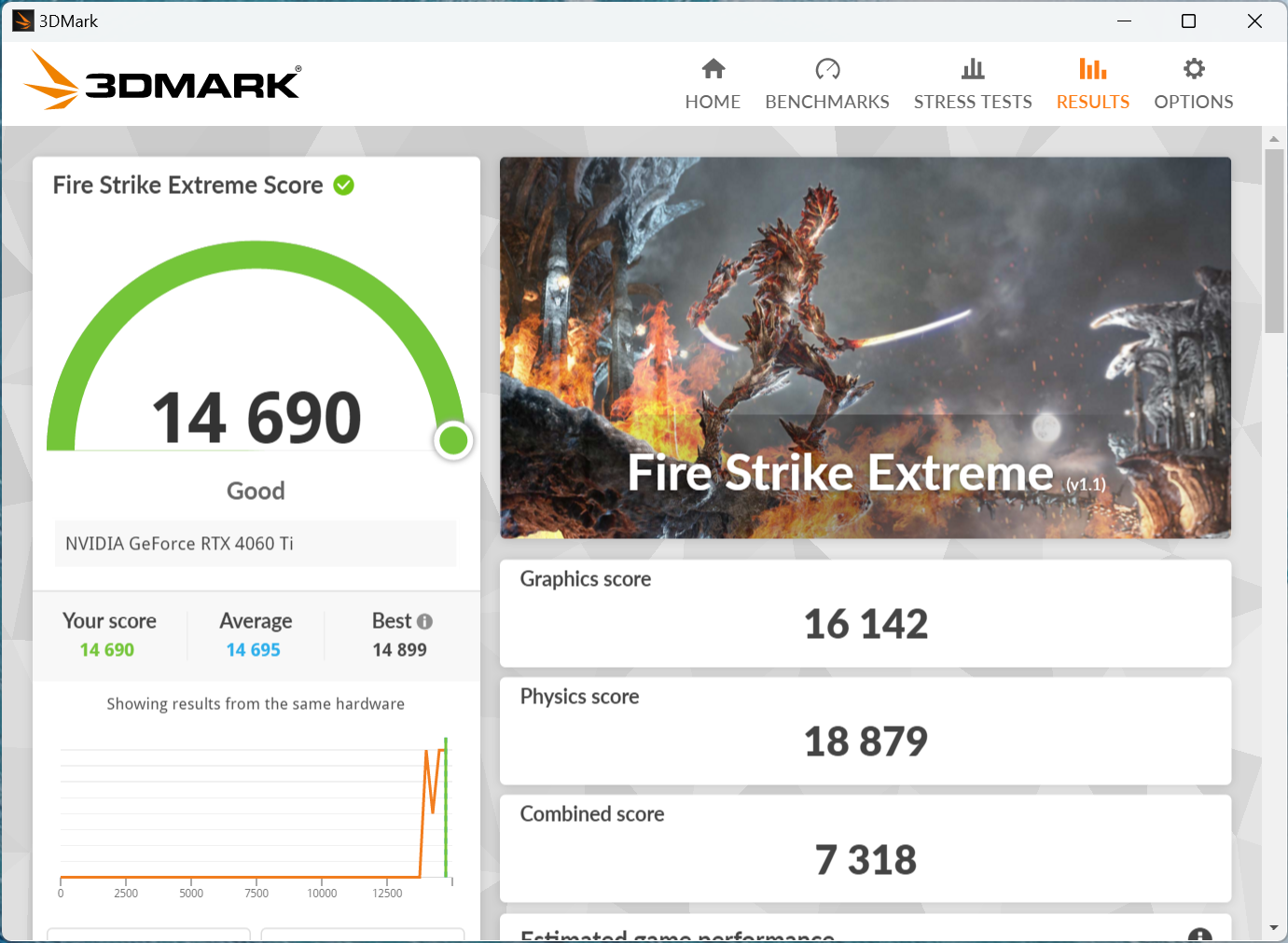
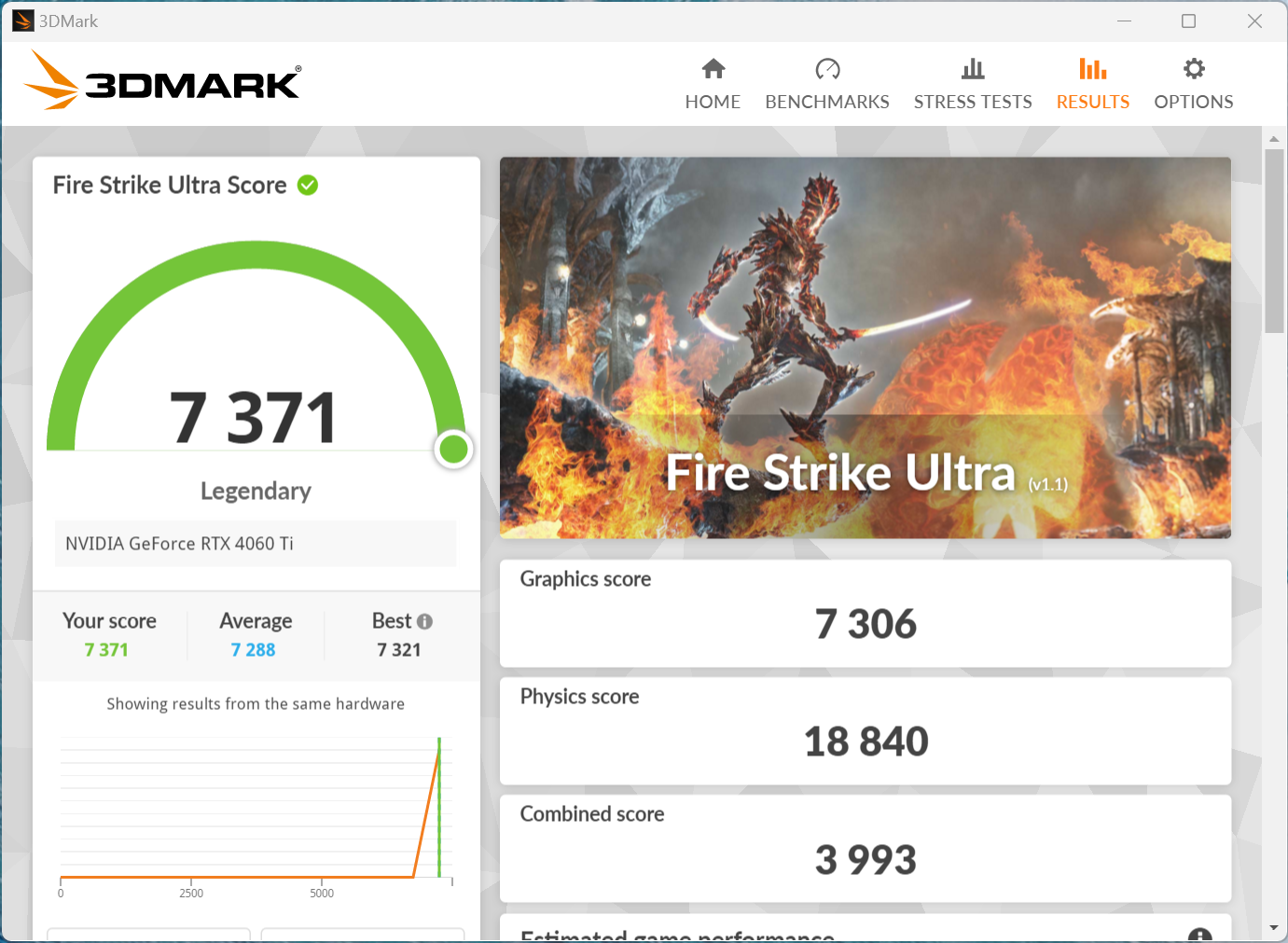
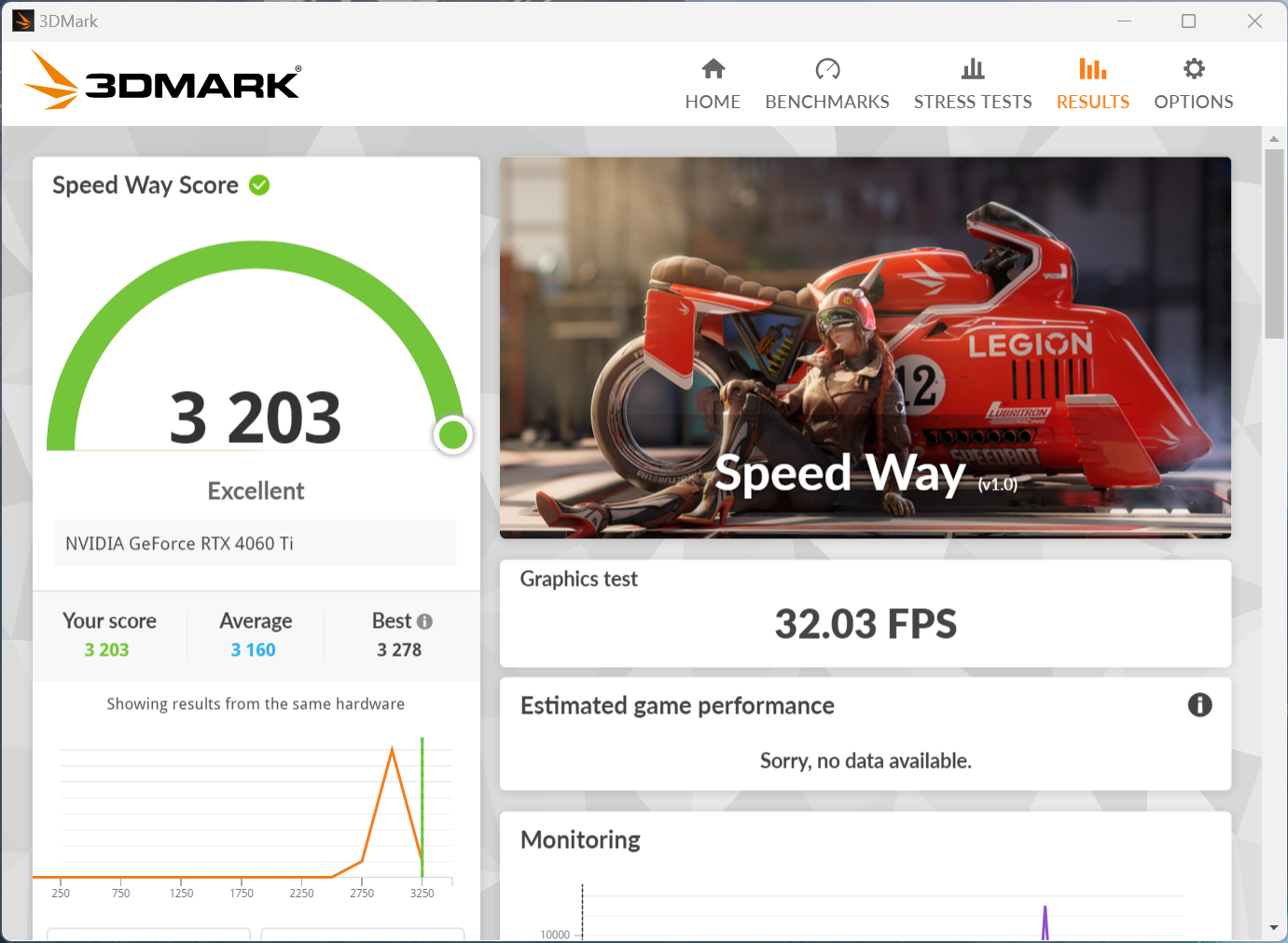
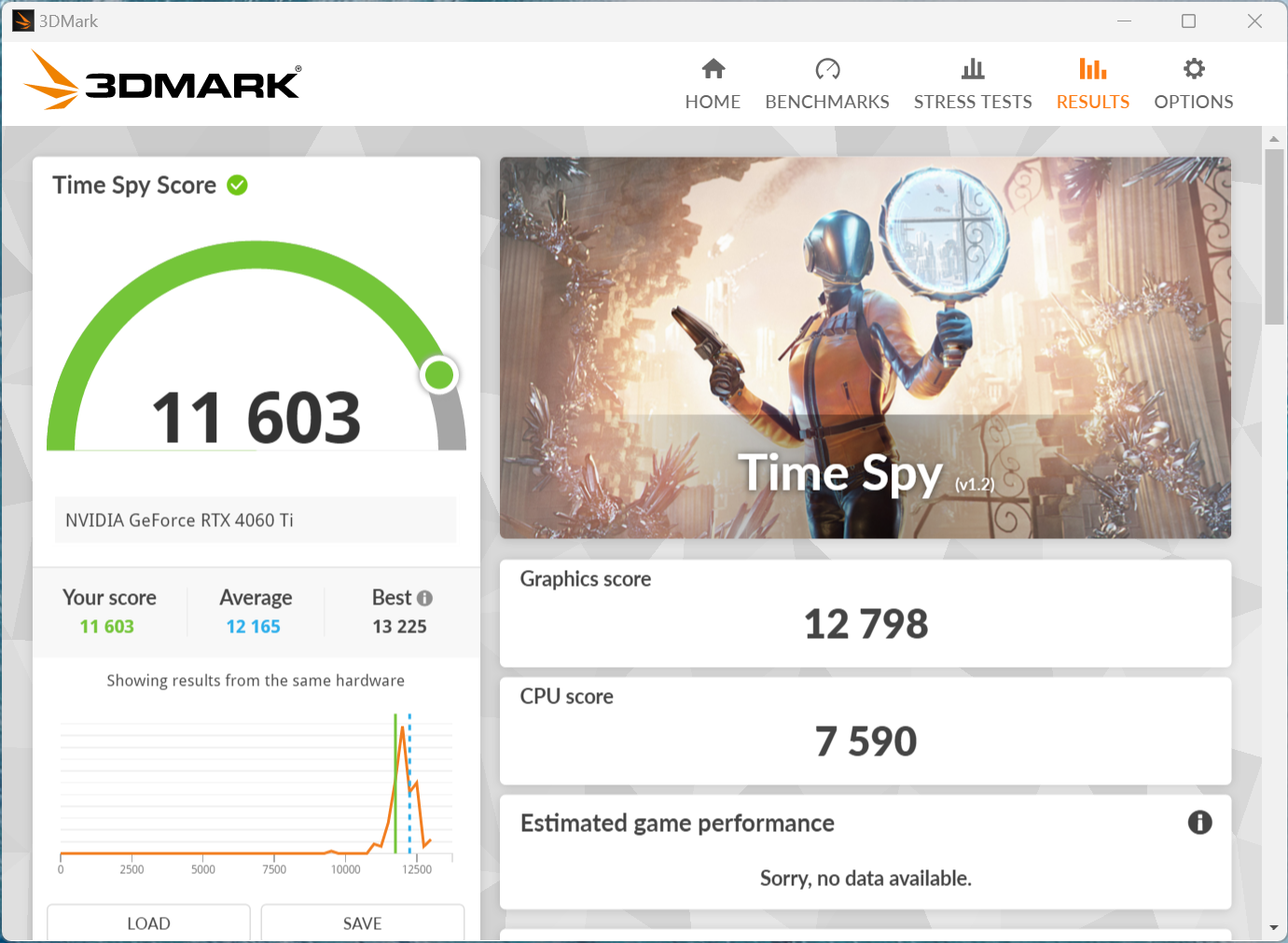
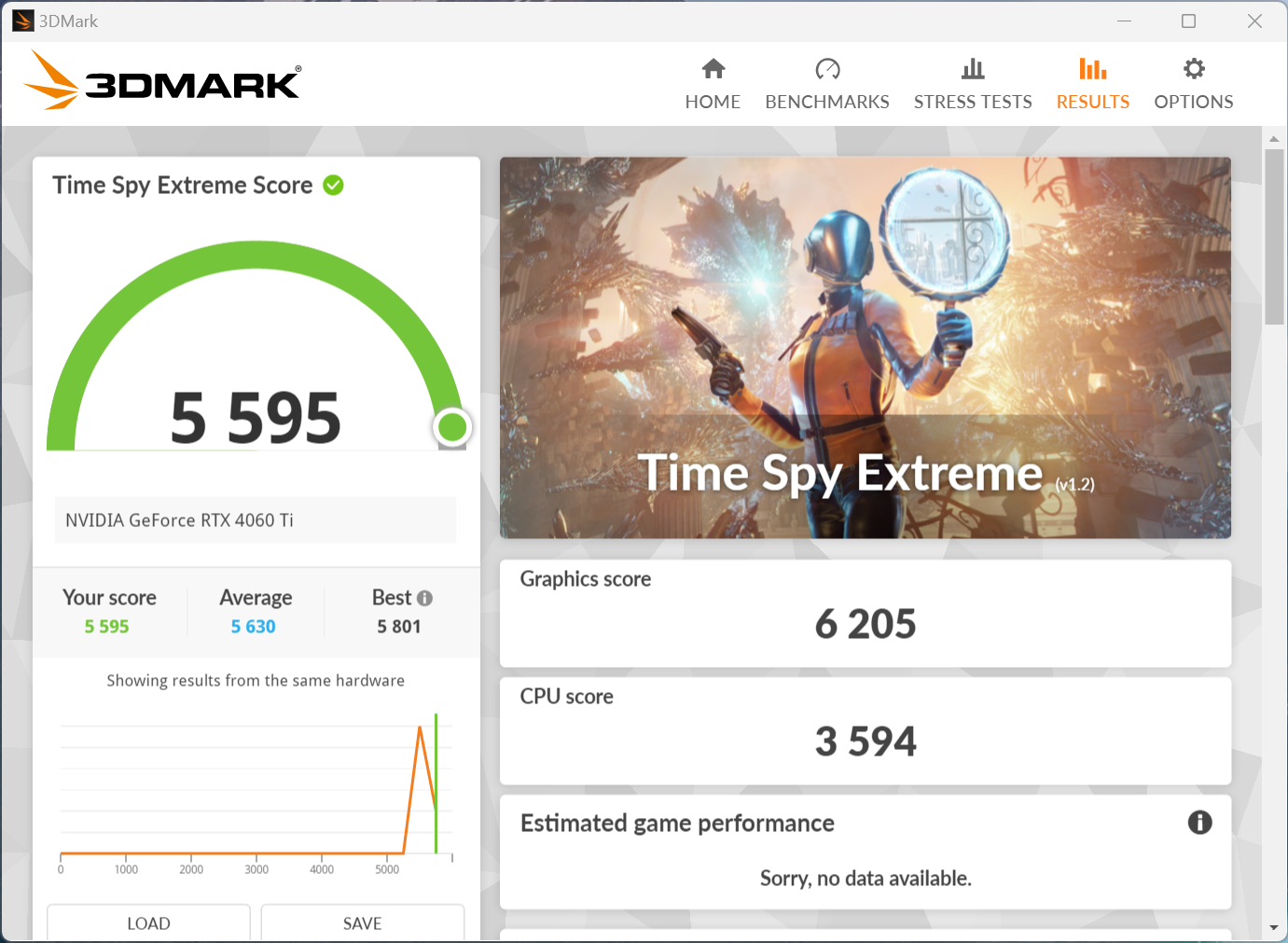
APISIX内存问题
作者: nick
日期: 2024-06-18
没有评论
最近在使用apisix做一个接入网关,遇到比较多的内存相关问题:
使用apisix版本3.7.0,生产集群中遇到内存持续缓慢增长的现象,google后官方确实有个etcd timer相关的内存泄漏bug:https://github.com/apache/apisix/pull/10614
测试环境修复此bug后,压测验证仍存在内存增长问题。压测环境为
- 模拟随机报文发送(1k~1m) -> apisix (ext-plugin <-> JavaPluginRunner) -> Server — 1k tps压测几分钟后,系统出现oom
- 模拟固定报文发送(4k) -> apisix (ext-plugin <-> JavaPluginRunner) -> Server — 1k tps压测,openresty进程内存占用稳定
github中找到了类似的问题:https://github.com/apache/apisix/issues/8461,但官方并没有认可此bug并给修复。修改apisix/plugins/ext-plugin/init.lua后,重新进行1压测,内存已稳定。
推测为flatbuffers.builder的Clear没有清理buffer内存,为提高性能采用了复用的策略,在此场景1下会导致每个buffer都会增长到接近1m的大小,导致内存占满;
Ollama 模型验证
作者: nick
日期: 2024-05-27
没有评论
总体试用下来,qwen2:7b > llama3:8b > gemma:7b > qwen:4b
qwen2是最近刚出的,中文回答、代码生成效果都不错,llama3的中文比较糟糕,gemma:7b有时候生成的内容会有重复或者缺失,qwen4b只能算个demo
近期评论